《crash course》学习笔记

最近用碎片时间刷完了B站的crash course,虽然只是CS通识课,但是制作得特别精良,作为小朋友的CS入门课程很合适,我自己也温故而知新。本文把一些内容记录下来
这是视频的链接,crash course
我比较喜欢前面关于电路基础的部分,跟《编码》的内容差不多,可以配合学习
数学理论基础
计算机技术发展至今,代表了人类科技的最高水平。计算机的理论基础是二进制和布尔代数。因为二进制把现实世界映射到计算机的数字世界,计算机才能从最基础的加法计算开始,发展到对整个现实世界建模
二进制
二进制跟十进制基本类似,都是位置化数字系统。只不过十进制是逢十进位,而二进制是逢二进位。所以二进制只用到了两个数字0和1,后文会提到,这个特点使得二进制“刚好”适合计算机
由于二进制和十进制没有本质区别,所以十进制的各种运算规则,在二进制也适用
布尔代数
布尔代数解决的是逻辑运算的问题,而不是数字运算的问题。但是逻辑运算的true/false,“刚好”可以对应到二进制的1和0。所以布尔代数的理论,就可以应用到二进制的数字运算上
比如“与”运算符,真值表是1+1=1,1+0=0,0+1=0,0+0=0,跟二进制加法非常相似(只少了进位),所以接下来科学家就用逻辑电路实现了布尔代数的逻辑,进而解决了二进制运算的问题
编码
然而,光有数字还不够。现实世界除了数字,还有各种文字、物体等,无法仅仅用数字来表示。因此,这就涉及到编码。编码是数字到实体的映射,比如ASCII,规定每个英文字母对应一个数字,比如大写字母A对应的数字是65,用二进制表示是01000001。然后字符处理程序看到01000001,就知道是大写字母A。通过编码,计算机不但能处理数字,也能处理字符了
人列计算机
先不考虑逻辑电路,以二进制和逻辑门为理论基础,有多种方式都可以制造出计算机。比如在《三体》中描述了一种人列计算机,非常天马行空,但完全可以实现,并且也是冯诺依曼结构
人列计算机用到的也是二进制(用黑旗、白旗表示),逻辑门(用人扮演),但其中完全没有电路。比如“与门”需要3个人来组成,黑旗代表1,白旗代表0,只有当代表输入的2个人都举黑旗的时候,代表输出的人也举黑旗,否则他就举白旗。然后以此为基础,将许多“三人小组”叠加起来,同样可以构建出半加器等所有的计算机部件
所以,二进制和逻辑门才是最基础的。电路只是实现的方式之一,电路能实现的事情,靠人类阵列也能实现。但是显然,人列太慢了,还会出错,并且占空间,关键是也养不活
现代电子计算机
现代电子计算机用逻辑电路实现。二进制只需要用到2个数字,0和1,因此只需要两种状态就可以表示二进制。这使得计算机内部很容易用二进制来表示,比如电路开关,电平高低等
用电平表示0和1
计算机用高/低电平,代表1和0。于是现实世界的数字,就可以用一串1和0的序列来表示。之后就可以执行各种运算,这也是计算机最初的由来。不同的芯片电平范围不同,比如CMOS的电平范围是3-15V,TTL是0-5V
逻辑电路
能够表示1和0之后,接下来还需要有一种机制,使得电平能够切换。这是用逻辑电路来实现的,逻辑电路是现代电子计算机的基础
早期的计算机,用继电器(relay)制造,并不是纯电子的,有机械的成分。比如下图是用继电器实现的“非门”的示意图。当前面的电路接通,继电器产生磁性,把后面的开关断开,后面的电路就断电了。
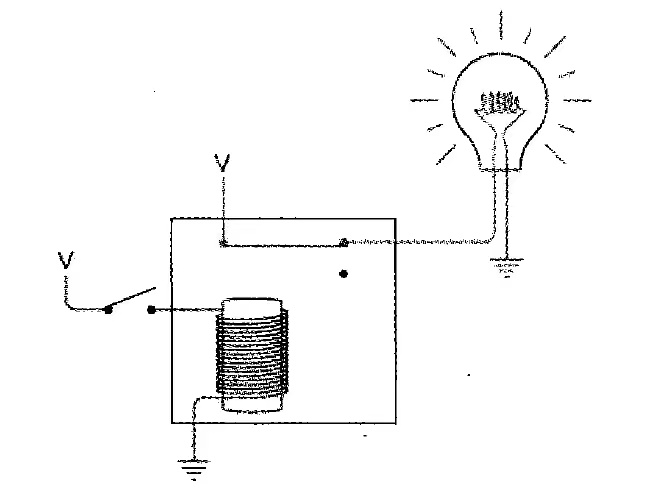
但继电器是机械装置,速度慢,易损耗,体积大,成本高,所以限制了逻辑电路的能力上限。后来发展出了真空管、晶体管,才有了现在的电子计算机。
关于逻辑电路,明白原理就可以了。再深究下去就进入了数字电路、模拟电路的领域,如TTL、CMOS等,不是CS的范畴了
门电路
通过逻辑电路实现布尔代数的逻辑运算,依赖的部件称为门电路(gate),有与门、或门、非门、异或门等,如下图,是与门和或门的电路实现
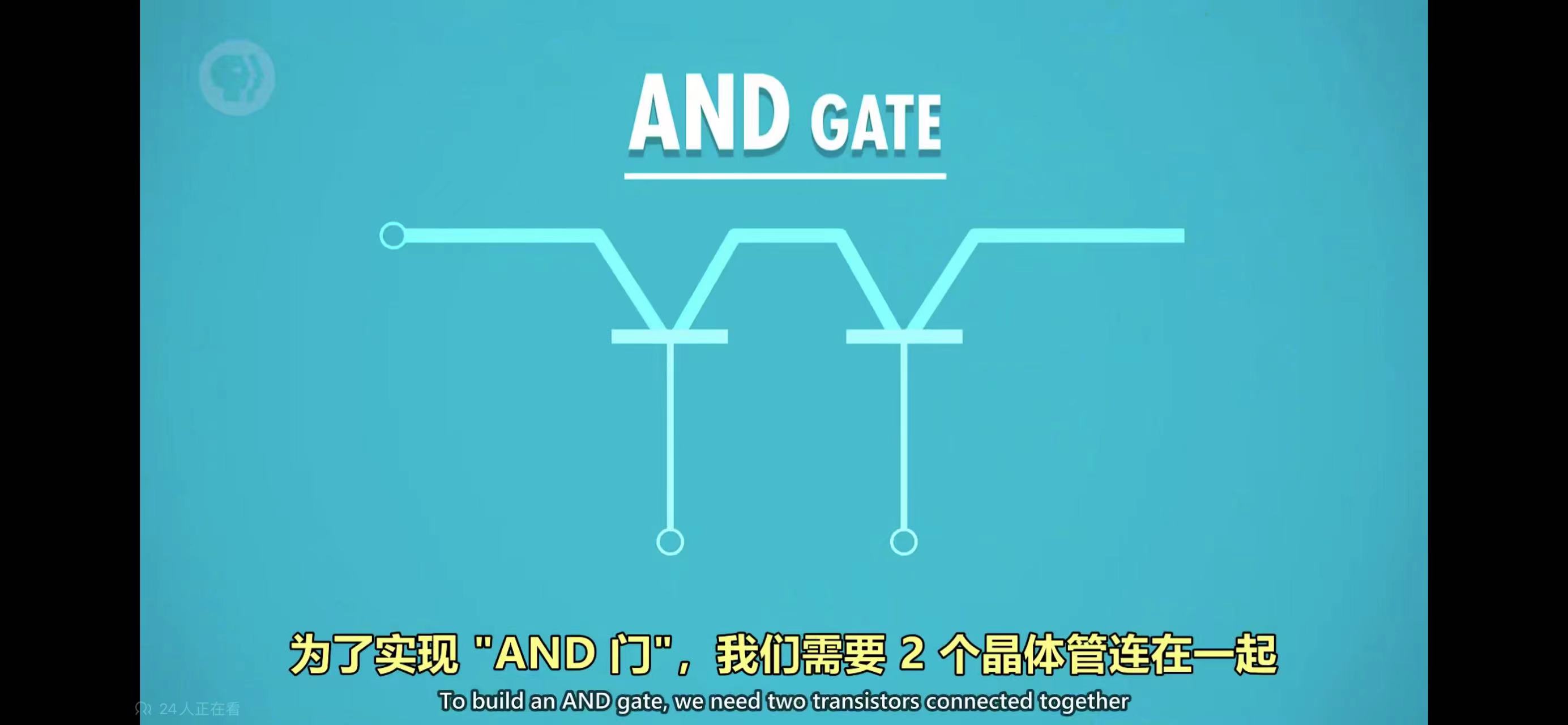
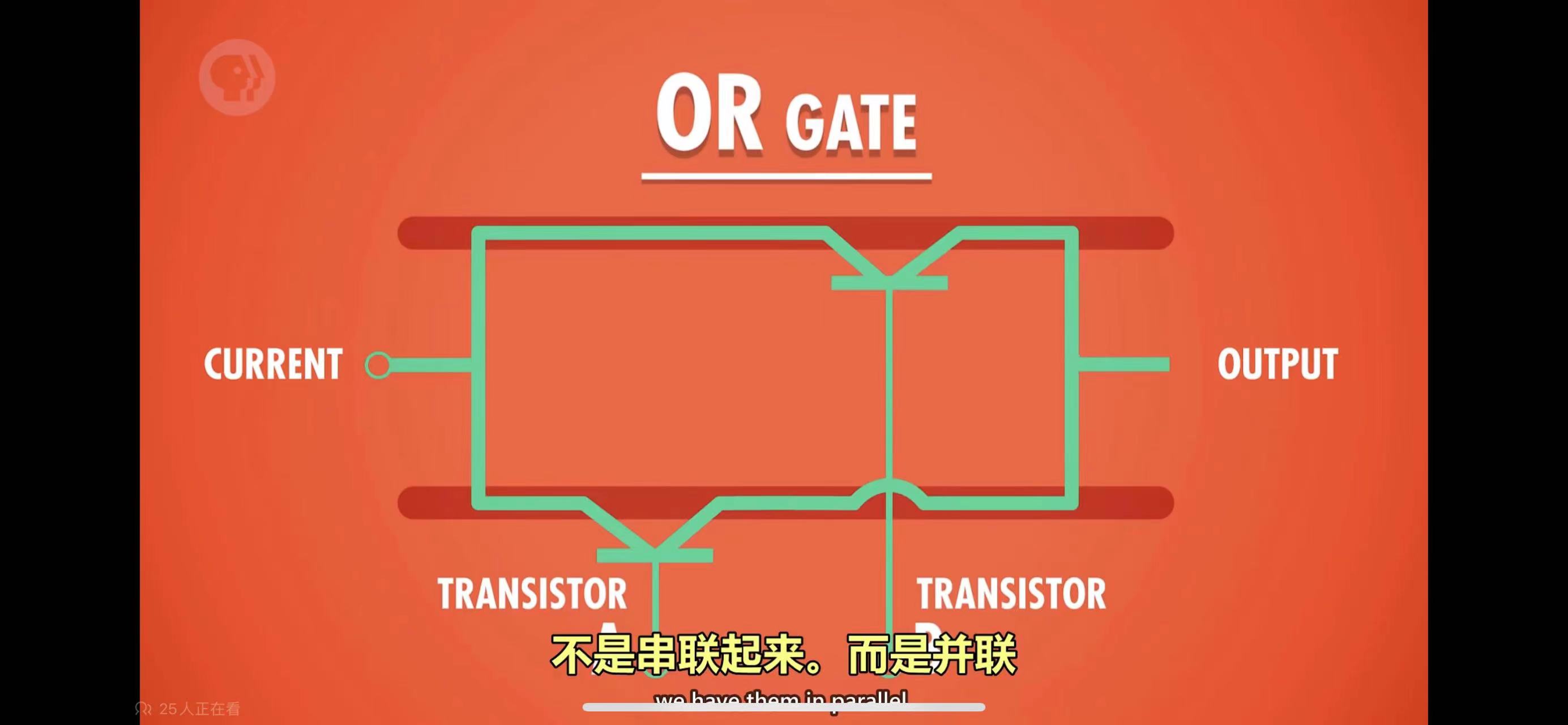
异或门稍微复杂一些,需要把与门、或门、非门组合起来实现
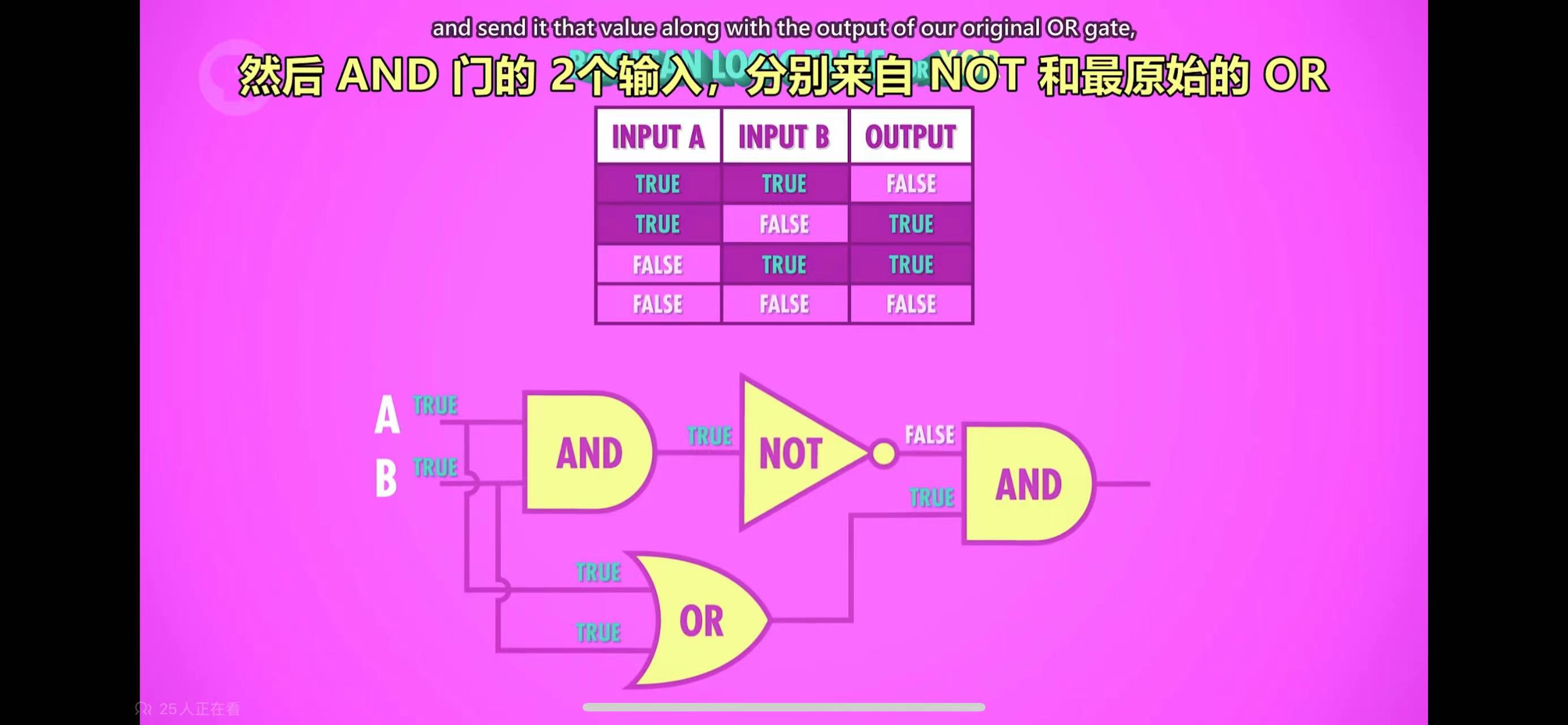
可以看到,门电路不太复杂,但是高阶部件是由大量的门电路组合而成的,电路图就极为复杂。所以把门电路抽象后,用符号表示,忽略其内部的实际电路结构,画更高层的电路图时,就不需要关注单个门电路内部的电路结构了。早在那个时候,就已经运用了抽象的思想。
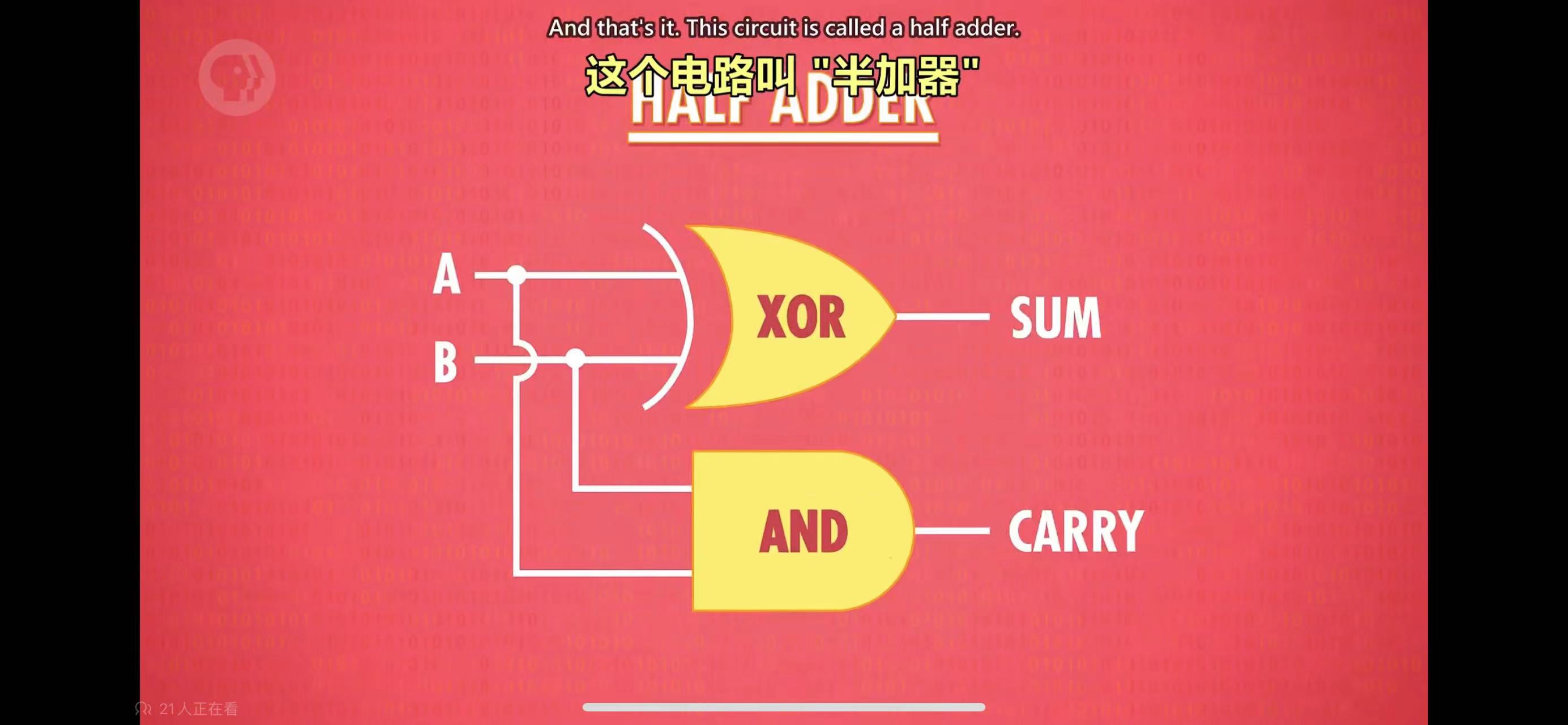
在门的基础上,组合做出了半加器、全加器、寄存器、ALU、CPU等更高层的部件,最终组合成计算机。比如下图,是半加器的电路,算是最简单的组合部件
程序执行
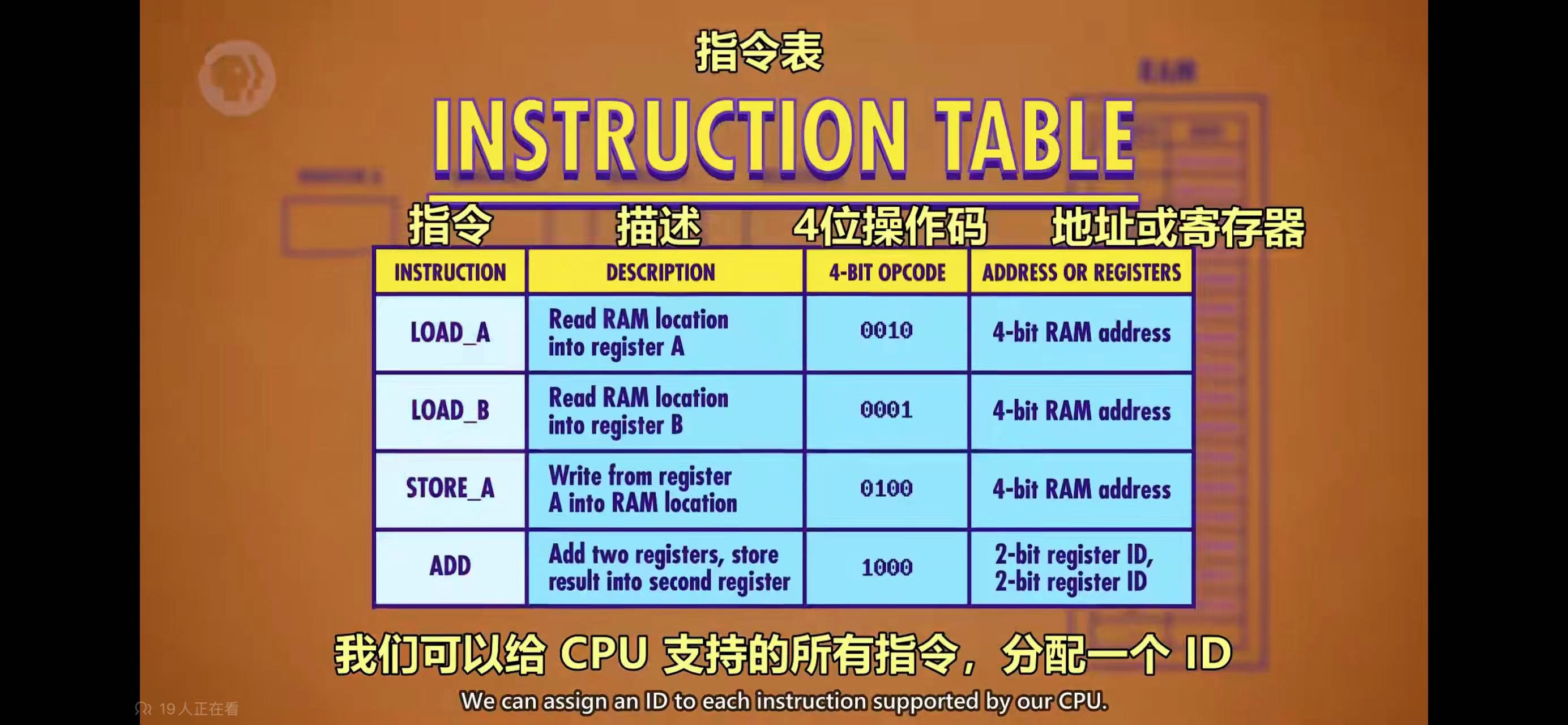
计算机的牛逼之处是能够运行程序,而运行程序归根到底是依靠机器码(机器语言)。CPU提供了一系列指令,最早的CPU只提供70多条指令,现在的CPU支持的指令有数千条。无论指令多少,程序能够做的事情,就是由这些最基础的指令决定的
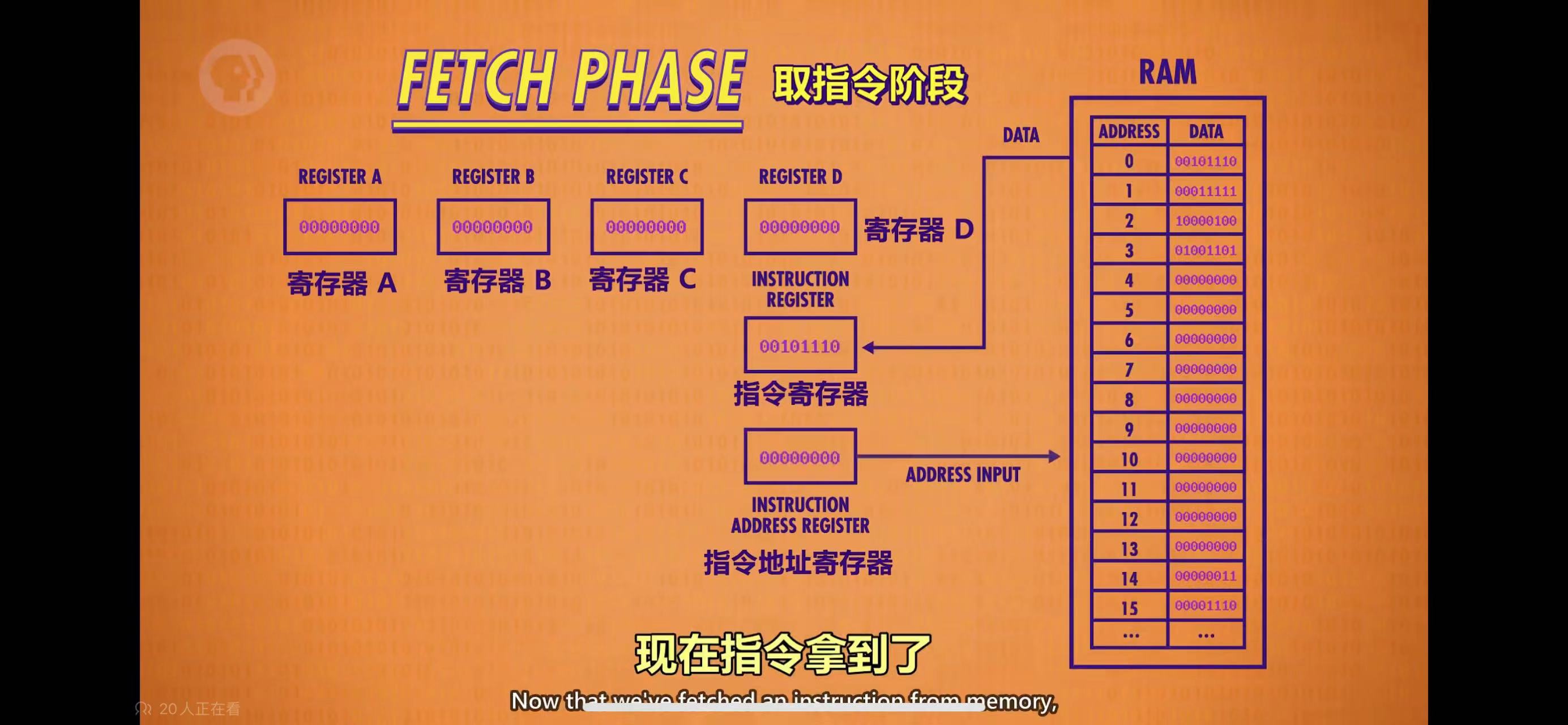
CPU在时钟周期里,按照取指 - 解码 - 执行的顺序,自上而下依次执行每一条指令,程序员写的程序,就是按照这个流程跑起来的,如下图:
现在的高级语言,最终会被编译成汇编语言,再由汇编器翻译成机器语言来执行,比如说最简单的一行if代码
1 | if(a>3) |
其实计算机是不认识if,a和3的,这条语句最后会变成
1 | load_reg_a xxx // xxx是变量a在内存中的地址 |
只有上面的load_reg_a,load_reg_b,sub,jump_neg才是计算机(准确的说是CPU)认识的指令,这些指令如前所述,都是由CPU提供的

一个额外的小问题是,程序是怎么进入内存的呢?前面的示例都假设程序(已翻译成了机器码)已经在内存里了,可以被CPU直接读取到指令寄存器里。但是实际上,程序并不会自动装载到内存里。早期的时候,是通过卡片读取器,将卡片上的程序装载到内存中,然后通知计算机开始执行。而现在,程序一般是保存在硬盘里,然后由操作系统负责装载到内存里的

高级语言
早期的程序员,需要直接用机器语言编程,可想而知难度很大,并且效率也太低了。所以产生了汇编语言,基本上类似于助记符,这样程序员就不需要写一串01010101这样的代码,可以用汇编语言写程序,然后由汇编器将汇编语言翻译成机器码,编程效率高了很多
汇编语言与机器码基本上是一对一的映射关系,主要是减轻了人脑记忆的负担。不过尽管如此,汇编语言的出现,已经可以算是编程语言的第一次重大突破
但是用汇编语言开发,与直接用机器语言开发一样,并没有屏蔽底层的细节,程序员依然需要思考使用什么寄存器和内存地址。所以后来又出现了高级语言,屏蔽了底层的细节,程序员只需要考虑逻辑,不用再关心内存和寄存器这样的细节。用高级语言开发的程序,会由编译器编译成目标架构的汇编语言,再由汇编器翻译成机器码。高级语言的出现,是编程语言的第二次重大突破,这个突破的意义,比汇编语言的出现更大

与汇编语言不同的是,一条高级语言的代码,最终会转化成多条机器语言。所以编译器的难度,比汇编器要大得多。这也是为什么有一门学科叫编译原理,但没有汇编原理
比如以下简单的语句
1 | c = a + b; |
最终可能会变成以下的机器码
1 | load_reg_a xxx // xxx是变量a的内存地址 |