修复性能问题

最近系统做了较大的架构调整,主要是把微服务的粒度拆得更细,很多本地调用换成了RPC。另外还增加了一些新的特性。整体来说,在性能测试中劣化比较明显,于是又花了将近一周时间优化性能。本文记录优化过程中的关键点。
降低CPU空载消耗
首先在环境上top,发现CPU的占用和load都很高。在空载状态下,CPU的占用就已经接近50%,这显然不正常。于是用perf工具,分析对cpu的占用
1 | perf record -u root -a –g |
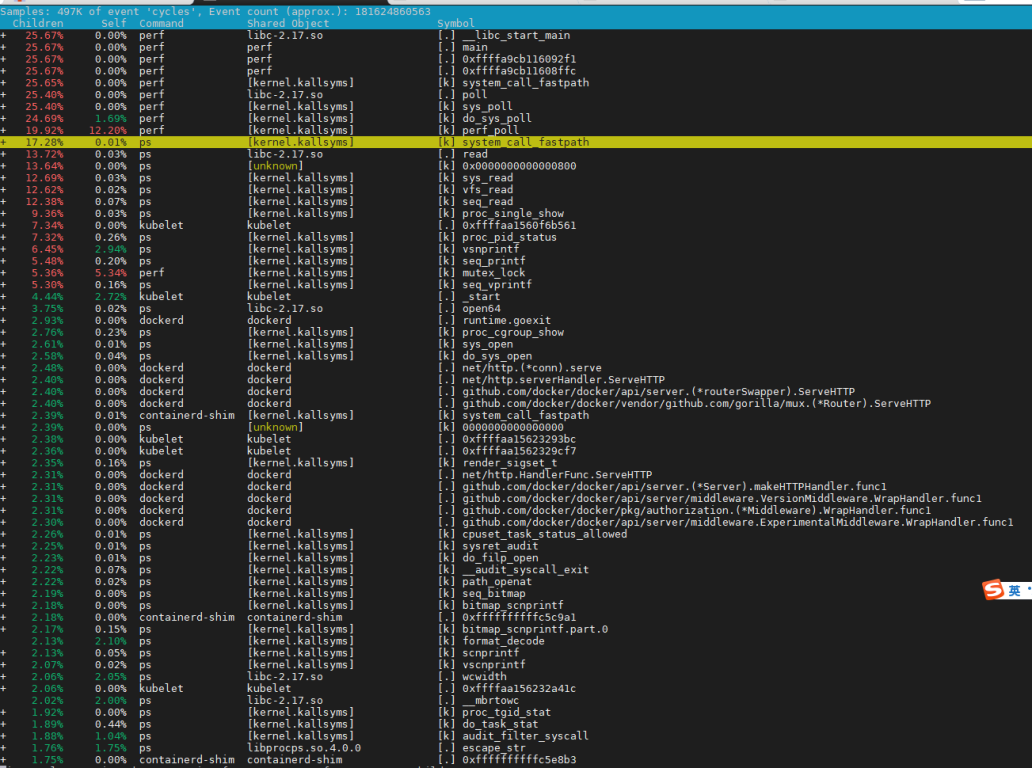
发现健康检查的shell脚本消耗了大量的CPU。主要是两个原因,首先是脚本执行太频繁,6s就跑一次;其次是脚本中写了大量的ps命令,而由于进程非常多,ps命令本身的消耗就很大。于是延长心跳检查周期,并去掉了脚本中不必要的ps命令。
通过上述修改,将空载状态下的CPU消耗减少到10%,提升比较明显。
优化RPC性能
此次微服务拆分后,RPC调用相比之前显著增多,RPC调用本身也成了一个瓶颈。
这部分想彻底优化比较困难,由于种种原因,rpc框架选型了servicecomb,跟HSF,gRPC等主流框架相比,本身性能就占劣势,临时要替换rpc框架也有一定风险。所以最后是做了2个优化。
首先是把通信协议从https切换到http,实测有少许提升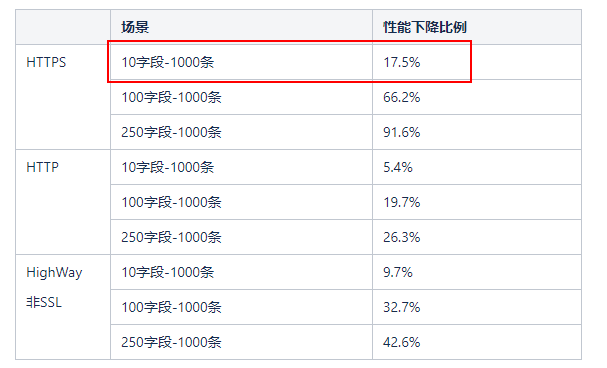
另外查询文档得知,servicecomb支持vertx模式,但是需要改造比较多代码,后续可以研究一下,应该还能提升一些性能
除了rpc框架本身的配置修改之外,又通过arthas trace,发现自己包装的client代码,在实际发起rpc调用之前,做了一些多余的动作
1 | private static final AtomicReference<Environment> SPRING_ENVIRONMENT = new AtomicReference<>(); |
1 | @Override |
在每次调用之前,会去配置文件里查询一些参数组装上下文。但是这些参数实际上在运行期不会变,可以认为是静态数据,不会有并发读不一致的问题。所以这里代码里的AtomicReference没必要,改成了简单的单例,减少了4ms时延。
增加缓存
分析几个典型场景发现,有大量的rpc调用都是为了查询模型的元数据(系统中有很多动态模型,与本文无关不展开)。实际上元数据的变化频率极低,并且重复查询很多,很适合使用缓存。于是针对这部分元数据增加了客户端缓存,减少了rpc重复调用,效果比较明显
修复频繁full gc问题
查看jstack抓到的线程堆栈信息,发现大量的线程处于BLOCKED状态。同时用MAT查看内存状态,发现很多HashMap节点,其中保存大量String。判断应该是BLOCKED线程持有的数据无法释放,最终导致频繁的full gc
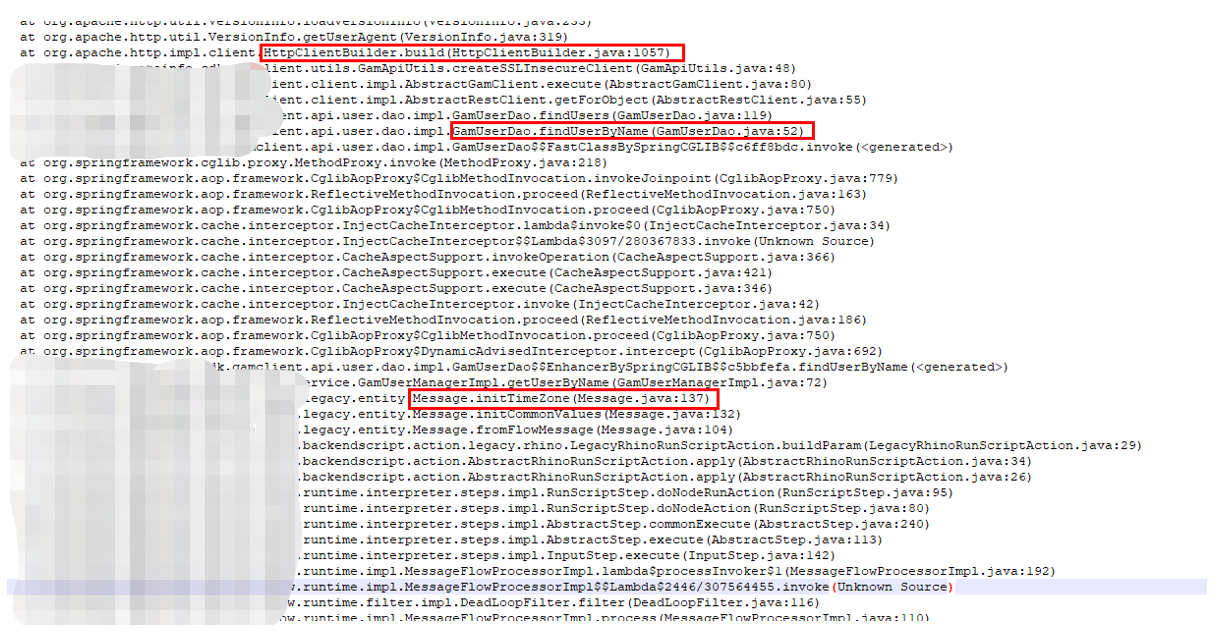
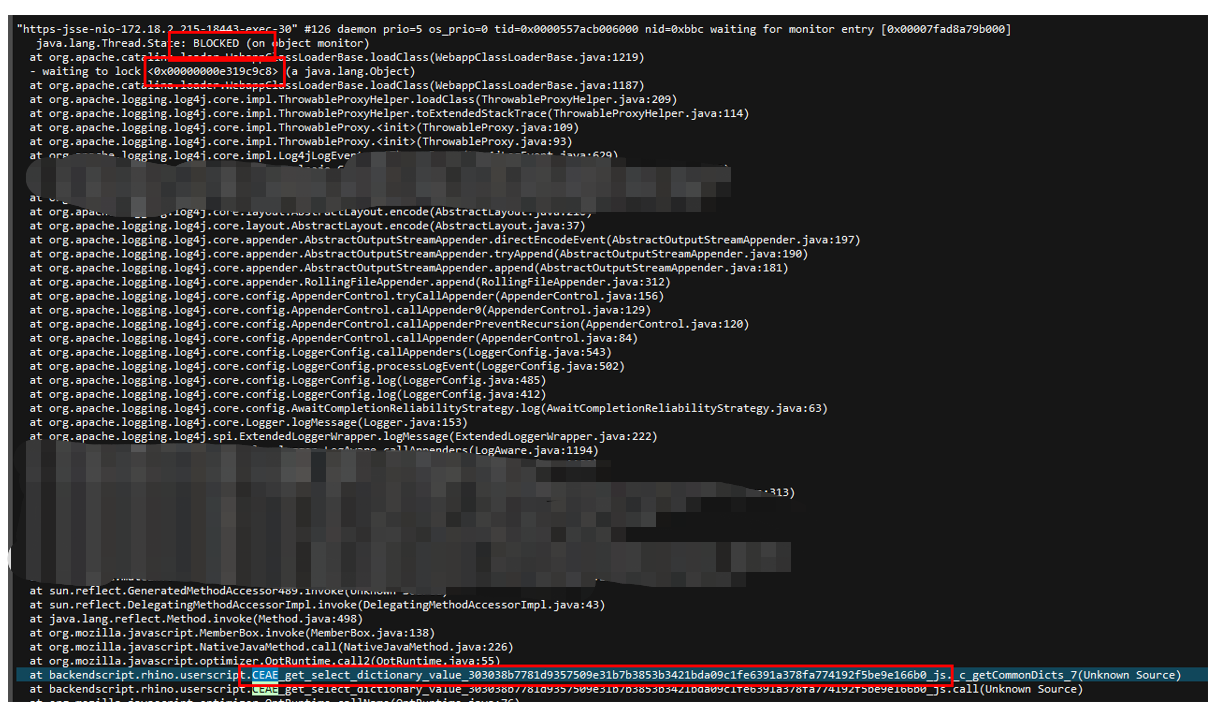
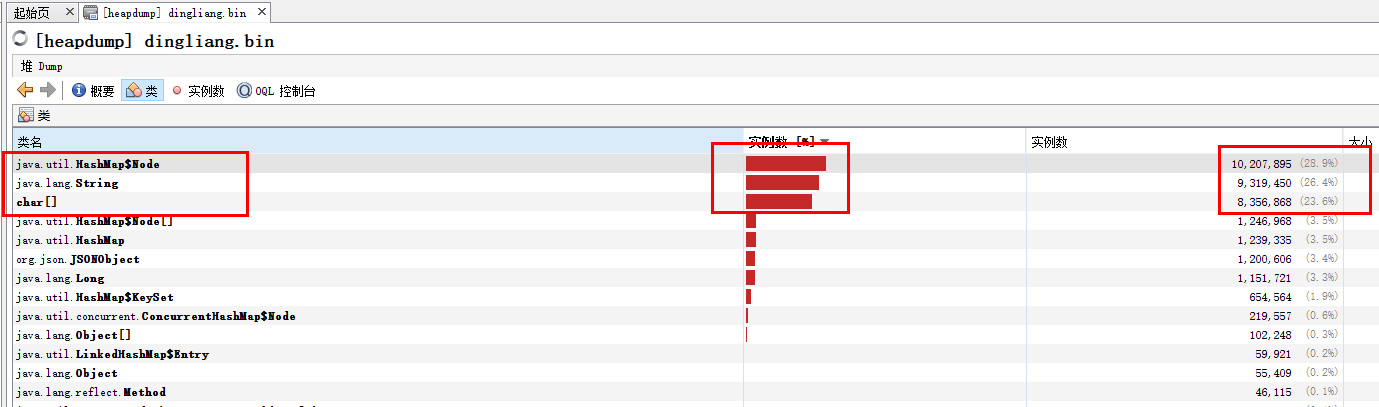
观察日志发现主要有2类问题比较频繁。
第一类BLOCKED情况,系统内嵌了rhino,支持执行用户自定义javascript脚本,当脚本执行出错的时候,调用log4j2打印堆栈。而自定义扩展的pattern类调用了loadClass()方法,由于脚本被动态代理机制反射生成动态类,在tomcat的classloader中加载不到,于是大量线程阻塞在这里。
第二类BLOCKED情况,是在发起一类调用之前,需要更新租户上下文,于是会创建HttpClient的实例发起请求。这里没有复用HttpClient的实例,并且每次创建实例的时候,都会去查询配置信息,最终走到catalina的synchronized代码块,引起了阻塞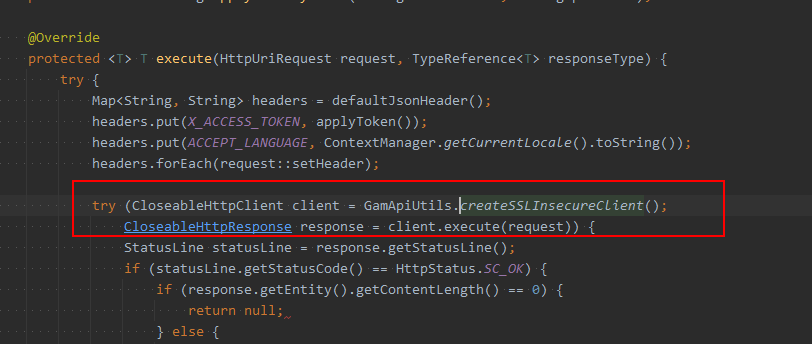
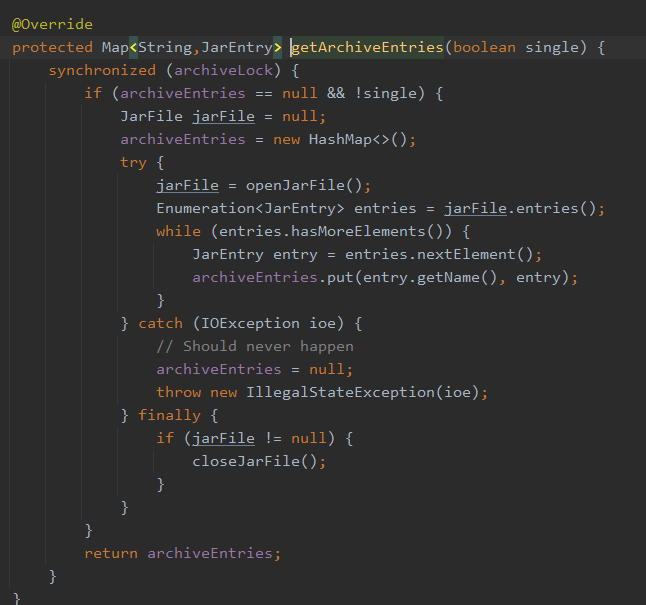
修改了这两处代码之后,没有再发生线程BLOCKED引发频繁full gc的问题
缩短http接口时延
另外测试发现,大量前台页面的ajax请求响应很慢。查看日志发现tomcat的access-log里统计耗时,跟controller方法trace统计出来的执行时间差距比较大
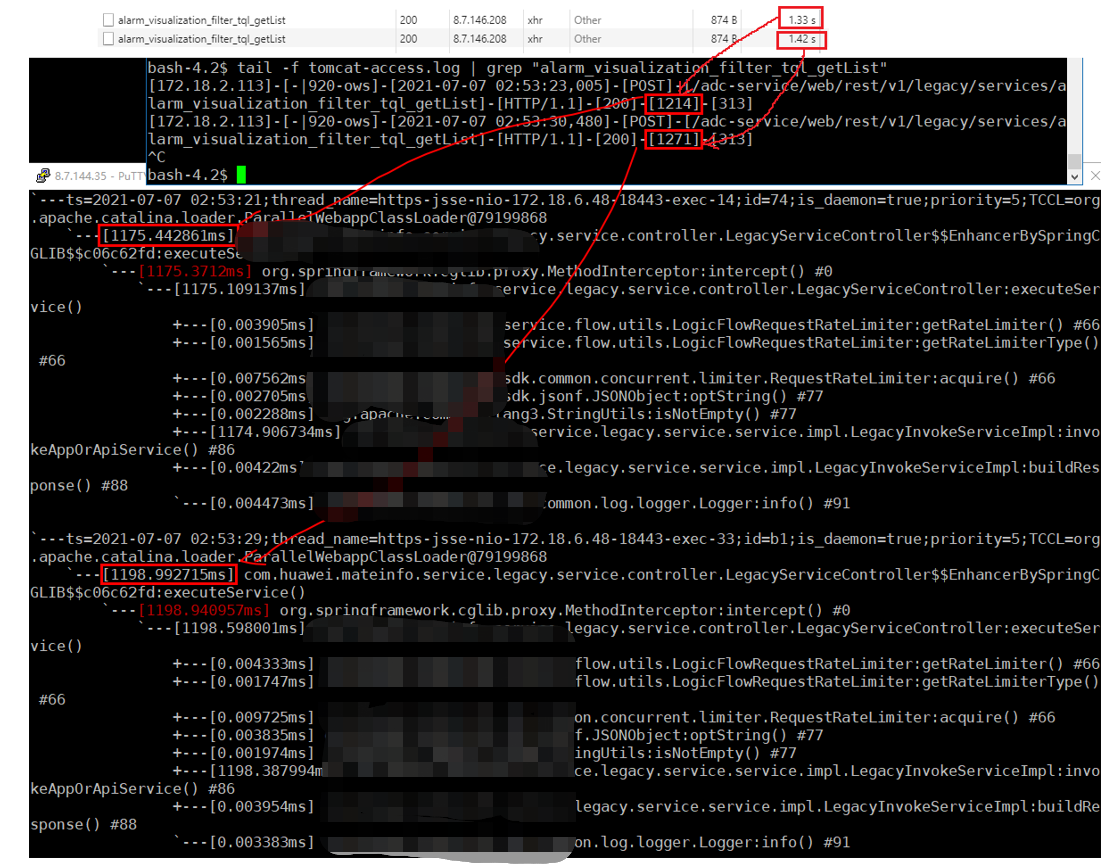
按理说这2个值的差距应该很接近,而且controller被trace本身就多消耗了一些时间,所以实际controller需要的时间应该更小,说明还是有多余的消耗。如果每个controller都多消耗了几十ms,对整体的响应速度影响还是很大的
基本上可以认为access-log的耗时 = filter chain + controller,并且filter chain是公用的。所以检查了filter chain的代码,发现确实有多余的消耗。比如对每个request,都需要设置租户上下文,会到ZK查询租户是否初始化成功。通过设置缓存,缩短了查询时间。排查了整个filter chain,对其中的filter都做了类似的优化,总共减少了大约30ms的时延
重写低质量脚本
系统支持自定义扩展脚本,也就是前面提到的javascript脚本,在rhino里执行。其中有些脚本的质量很差,写了低效率的查询语句,或者死循环等等。把这部分脚本找出来逐一修改,也提升了很多后端接口的性能。但这些基本上属于单点问题,也不具备可复制性,本文就不逐一展开了。