当前系统架构的感想

对公司目前系统架构的一些关键点的总结
应用垂直化和服务化
应用之间是相互隔离的,因此一个应用down掉并不会影响整个系统的可用性。当然如果提供关键服务的应用挂了,那么依赖此服务的应用也没法正常工作,这是不可避免的,只能尽量减少强依赖
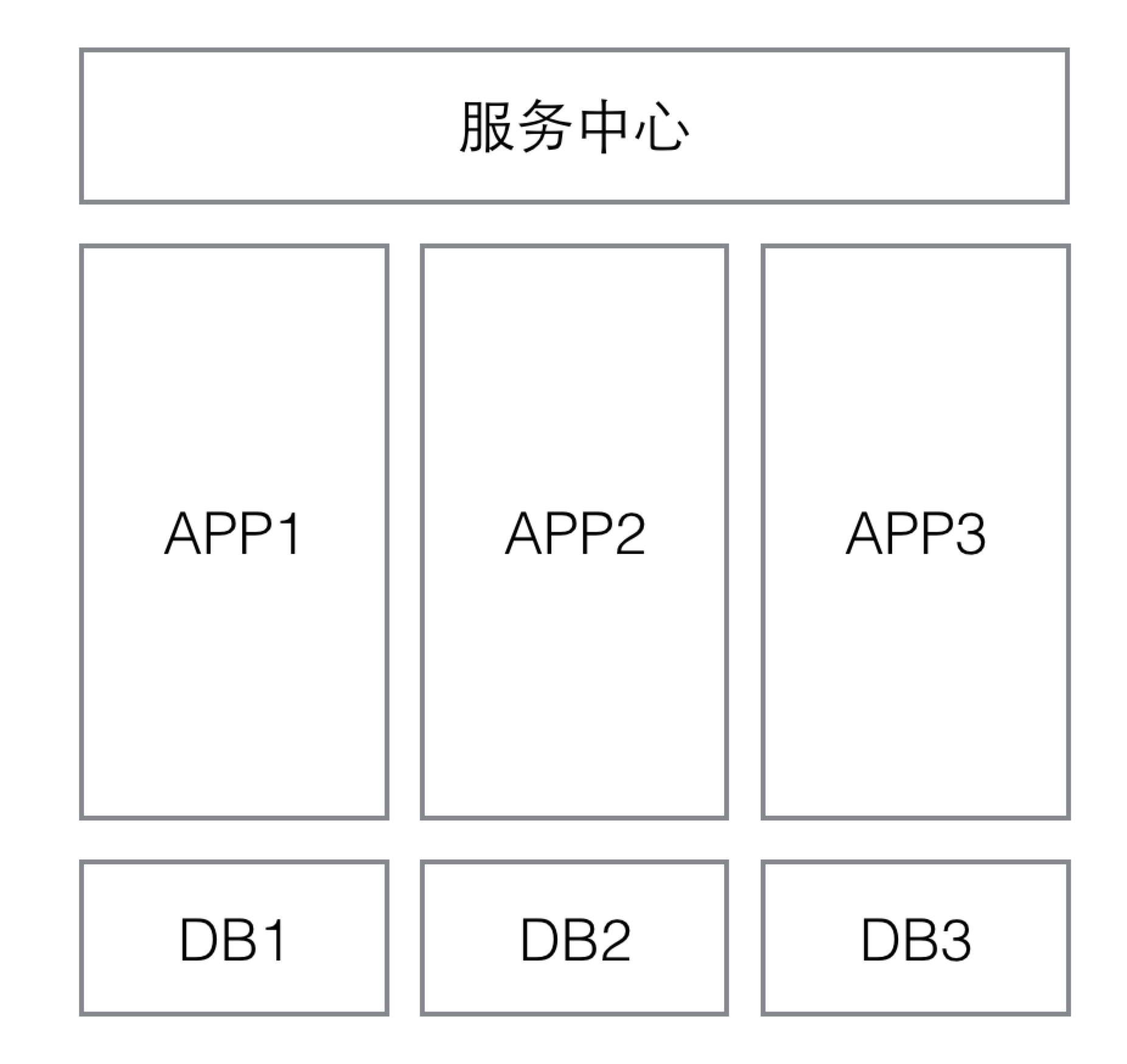
这就涉及到服务相互调用的问题,也就是服务治理。以前我们的做法是用nginx作为服务中心,用url来路由,这当然是很简陋的做法。现在的系统有专门的分布式服务框架来做这件事,叫做HSF。
另外作为服务的发布方,也需要有意识地自我保护。当提供一个服务的时候,要考虑如果此服务被外部频繁调用,或者错误地调用,是否会导致自己出现故障。不能轻易地发布任何一个服务,需要考虑发布此服务对自身系统的影响。
去中心化设计
HSF作为分布式服务框架,是上述架构能够落地的关键中间件。在实践中,HSF经受住了大规模调用的考验,其中很关键的一个设计原则就是“去中心化”
比如下图这种架构,就是一种“中心化”的服务框架:
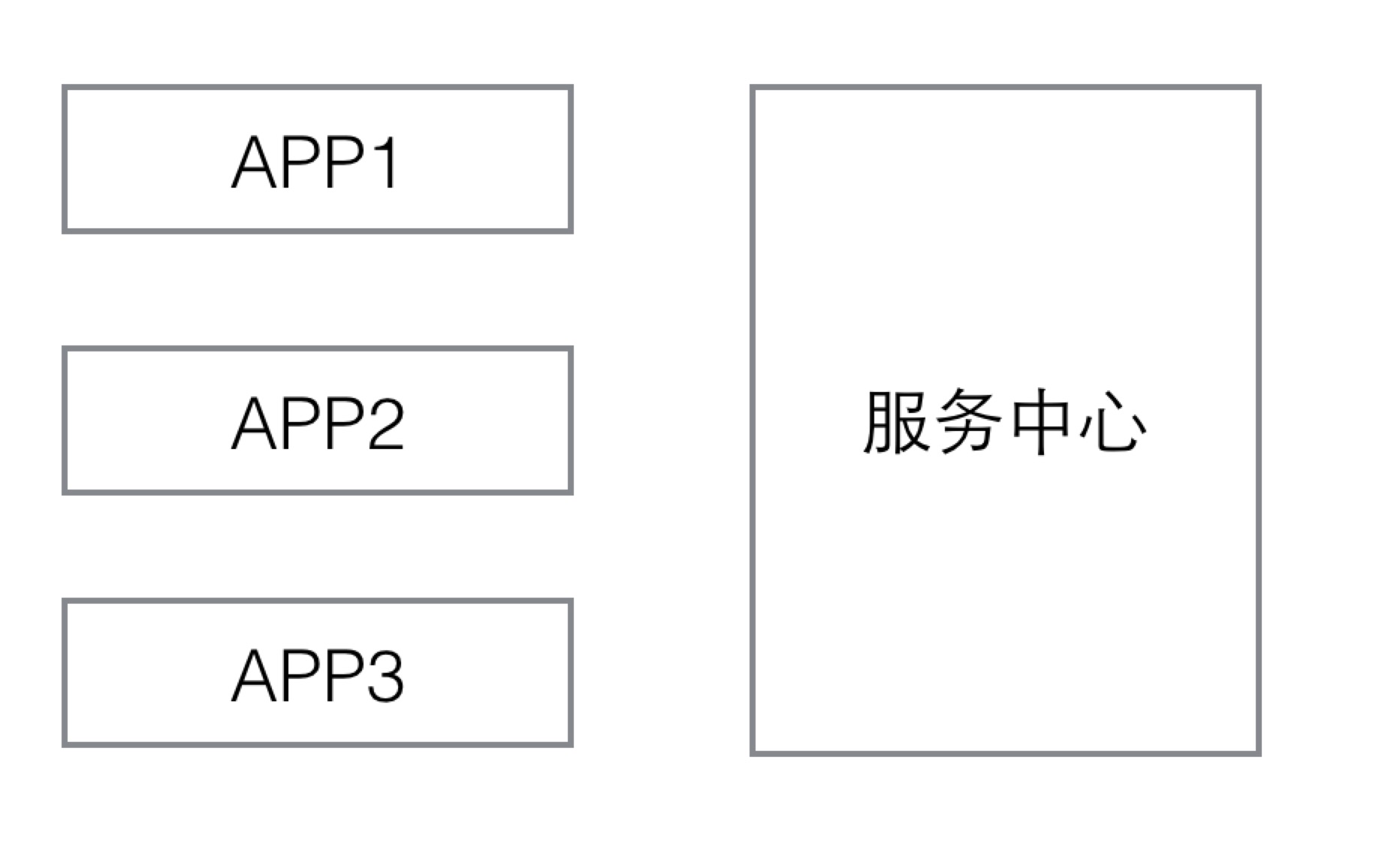
很容易看出,服务中心成了一个中心节点,如果服务中心挂了,所有的应用都会故障。并且服务中心的负担非常重,随着越来越多的服务上线,服务中心就需要不停地扩容。所以“中心化”是一种不可取的设计思路
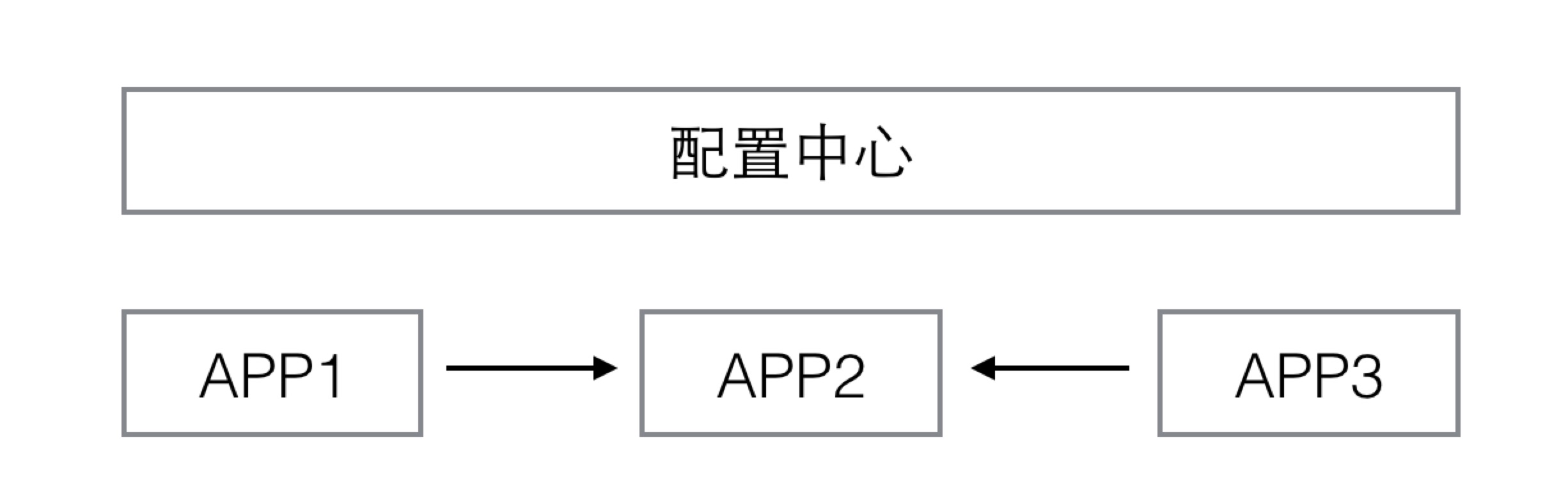
去中心化的架构,不再有服务中心的概念,应用之间是相互直连的,仅在必要的时候,将自己发布的服务信息上传到配置中心,以及从配置中心拉到自己依赖的服务信息。配置中心虽然也是一个中心节点,但是它比服务中心要轻量级得多。而且客户端自身一旦拉到了服务信息,就会把服务信息缓存下来,所以配置中心短暂地不可用并不会导致系统整体瘫痪。
当然HSF在背后还做了很多的工作,比如限流、服务链路监控、路由优化等,但是本文不展开,只提一下去中心化的概念。
分库分表
系统中有几张大表,已经很难在SQL层面解决性能问题。因此除了缓存以外,在数据库层面也做了分库分表。
分库分表本身并不是非常困难,难的是如何对应用层保持透明。如果数据库层面的变化需要应用层感知,不但业务代码会很丑陋,而且数据库变更或者扩容的时候,就需要应用也跟着修改。
系统的解决方案是TDDL,TDDL在客户端表现为jdbc的实现,所以跟spring等上层框架都是无缝兼容的。和HSF类似,TDDL也遵循去中心化的设计,也有一个配置中心,根据应用配置的APP NAME,找到实际的数据库地址,应用和数据库也是直连的,并没有经过一个中心服务中转
主链路和服务降级
主链路指的是系统最后的底线。比如商城类的系统,能够完成下单就是系统的底线。主链路图就是把支撑此功能的所有服务和接口,都在图上画出来,这是需要花费人力梳理的。对于非常庞大的系统,主链路图也会非常复杂。
有了主链路图,才能清楚在系统压力最大的时候(比如大促和秒杀),为了保障最核心的功能,哪些服务是不能挂的。接下来就可以把其他分支的功能想办法转化成弱依赖,或者增加功能降级的开关。
部署
部署这块我觉得也做得非常好,是让我印象最深刻的部分。以前的公司,只有我和另外一个核心人员,可以独立承担系统的部署上线。可是现在的公司,即使最小白的同事,也可以在工具的支撑下把代码安全上线,出了问题也可以快速回滚,让系统回到正常状态。
要达到这个效果,既需要制度保障,也需要自动化工具的强力支撑。
几个环境是相互隔离的,开发的时候系统运行在开发环境,并有与之匹配的开发数据库;然后会上预发环境,这时已经连接的是生产环境数据库,但是并不会有流量进来。在测试OK之后,才进入生产环境。如果是比较关键的系统,还可以灰度发布。
运维监控
运维监控是另一个做得非常好的地方,每一个应用都会接入监控系统。服务调用的链路、访问数据库的记录等等,都会完整地记录并展示出来,对定位问题非常有帮助
此外,监控系统还会监控核心业务指标,比如订单量。如果某个时间点订单量出现异常的大规模下滑,很有可能就是系统出现了问题,相关运维人员就会马上接到预警通知。类似地,如果订单量突然急剧攀升,运维人员也会收到通知,提高警惕并准备可能的扩容。